Madeline SchiappainTowards Data SciencePopular Downstream Tasks for Video Representation LearningA summary of the common downstream tasks used to evaluate video representation learning for long, instructional videos.·7 min read·Jun 9, 2021--1--1
Madeline SchiappaCovid-19: Just the FactsA summary of the information you need to understand Covid-19 and how it affects you. Info is from multiple sources for fact checking.·8 min read·Nov 4, 2020----
Madeline SchiappainTowards Data ScienceUnderstanding the Backbone of Video Classification: The I3D ArchitectureA summary of the I3D model. Commonly used for classification of videos or to extract features of videos for other tasks.·4 min read·Jun 7, 2020----
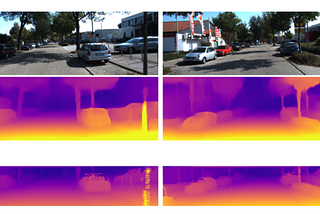
Madeline SchiappainTowards Data ScienceRecognizing Depth in Autonomous DrivingUnsupervised deep learning depth prediction for image sequences·9 min read·Oct 15, 2019----
Madeline SchiappaA Review on Quantum Image ProcessingThis paper is a review of research in quantum image processing (QIP), storage, and retrieval.·19 min read·Sep 24, 2019----
Madeline SchiappainTowards Data ScienceDeepLabv3: Semantic Image SegmentationThis article summarizes work from Google DeepLabv3 that improves semantic segmantic tasks compared to the state-of-the-art models.·5 min read·Sep 24, 2019----
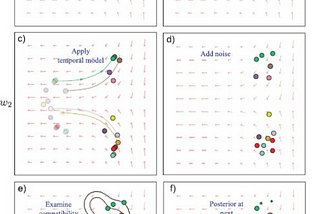
Madeline SchiappainTowards Data ScienceAutonomous Driving: Intro into SLAMSLAM is the process where a robot/vehicle builds a global map of their current environment and uses this map to navigate or deduce its…·7 min read·Aug 18, 2019--1--1
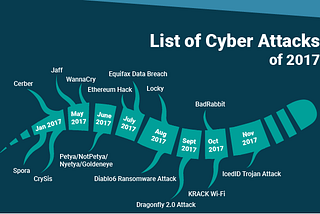
Madeline SchiappaCyber Training Through Games and AIThis article will briefly go over some of the current trends in cyber training and simulation.·10 min read·Jun 21, 2019----
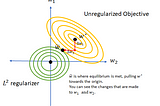
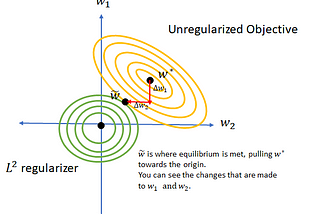
Madeline SchiappainTowards Data ScienceNorms, Penalties, and Multitask learningAn introduction to statistical norms and how they are used to improve the generalizability of a model.·5 min read·May 31, 2019--1--1
Madeline SchiappainTowards Data ScienceHow do Graph Neural Networks Work?GNNs encode graphical representations, but what are they and how do they work? Who uses them? This post will provide a brief overview.·6 min read·Apr 17, 2019--1--1